zarx said:
You are confusing completely unrelated things again. processing multiple texture layers in a single pass is a very old feature that all modern hardware has and all games utilize. Multi pass rendering is completely different and unrelated. Differed rendering is a multi pass rendering technique, the whole point is to separate geometry processing and shading to separate passes.
Tiled textures is also a completely different thing to tiled rendering. Most games since the dawn of 3D graphics have used repeated textures to saver production resources as well as for performance reasons. But that is not what tiled rendering is. Tiled rendering splits up the framebuffer into smaller sections, and then renders each section separately. |
i wasnt talking about mutipass with tiled textures, i was talking about tiled textures, the deffered rendering and multipass in three separate topics
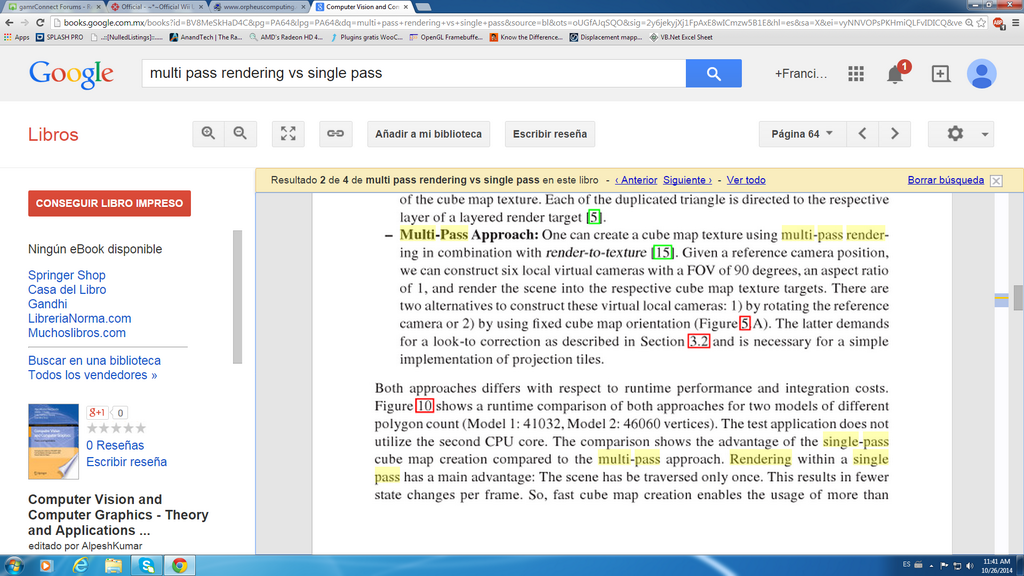
1.-multipass rendeinring as the name suggests requires the use of the pipeline multiple times for one work and single pass you use it one time so obviously that means less use of the ipeline to achieve a task, in the sdk information they tell us that 1080p or 720p can be done on a single pass. I woudnt call singl pass a old feature since was implemented on directx 8 and wasnt avalable before it
http://www.orpheuscomputing.com/downloads/ATI-smartshader.pdf
"
The key improvements offered by ATI’s SMARTSHADER™ technology over existing hardware vertex and pixel
shader implementations are:
• Support for up to six textures in a single rendering pass, allowing more complex effects to be achieved
without the heavy memory bandwidth requirements and severe performance impact of multi-pass
rendering
Every time a pixel passes through the rendering
pipeline, it consumes precious memory bandwidth as data is read from and written to texture
memory, the depth buffer, and the frame buffer. By decreasing the number of times each pixel on
the screen has to pass through the rendering pipeline, memory bandwidth consumption can be
reduced and the performance impact of using pixel shaders can be minimized. DirectX® 8.1 pixel
shaders allow up to six textures to be sampled and blended in a single rendering pass. This
means effects that required multiple rendering passes in earlier versions of DirectX® can now be
processed in fewer passes, and effects that were previously too slow to be useful can become
more practical to implement
"
2.-For the deffered rendering i just provided the article about the limitations on 360 sicne they needed 12MB gbuffer and since they didnt have it in the second article is explained that they had to use gpu parallelism and+cpu while the ps3 had to use 5spus out of the 8 that ps3 has(one spu is for the SO); doing it that way they can achieve the technique but also consumes large amount of rendering power, maybe still less than forward rendering but perfromance still wont be as good if they had enough memory bandwidth to do it the normal way. Wii U has enough bandwidth to sore triple framebuffers on 10.8MB and for the gbuffer would be about 8.64MB, with that in mind its clear that the deffered rendering on wii u will not take to much shader power as it took in last generation consoles and also will be better than using forward rendering, i wont deny that amost 9MB for the gbuffer is a lot bandwidth consumption, but seeing that triple frembuffers of 720p are just 10.8MB that still leaves edram room for other things and by trading bandwidth we can save up a lot shader power for other rendering purposes
yes is true that deffered rendering is multipass, but compared to forward rendering requires less passes, in fact only requires two passes while forward rendering would require that or more for the complex material/light combination
https://hacks.mozilla.org/2014/01/webgl-deferred-shading/
"
Forward rendering
Today, most WebGL engines use forward shading, where lighting is computed in the same pass that geometry is transformed. This makes it difficult to support a large number of dynamic lights and different light types.
Forward shading can use a pass per light. Rendering a scene looks like:
This requires a different shader for each material/light-type combination, which adds up. From a performance perspective, each mesh needs to be rendered (vertex transform, rasterization, material part of the fragment shader, etc.) once per light instead of just once. In addition, fragments that ultimately fail the depth test are still shaded, but with early-z and z-cull hardware optimizations and a front-to-back sorting or a z-prepass, this not as bad as the cost for adding lights.
To optimize performance, light sources that have a limited effect are often used. Unlike real-world lights, we allow the light from a point source to travel only a limited distance. However, even if a light’s volume of effect intersects a mesh, it may only affect a small part of the mesh, but the entire mesh is still rendered.
In practice, forward shaders usually try to do as much work as they can in a single pass leading to the need for a complex system of chaining lights together in a single shader. For example:
The biggest drawback is the number of shaders required since a different shader is required for each material/light (not light type) combination. This makes shaders harder to author, increases compile times, usually requires runtime compiling, and increases the number of shaders to sort by. Although meshes are only rendered once, this also has the same performance drawbacks for fragments that fail the depth test as the multi-pass approach.
Deferred Shading
Deferred shading takes a different approach than forward shading by dividing rendering into two passes: the g-buffer pass, which transforms geometry and writes positions, normals, and material properties to textures called the g-buffer, and the light accumulation pass, which performs lighting as a series of screen-space post-processing effects.
This decouples lighting from scene complexity (number of triangles) and only requires one shader per material and per light type. Since lighting takes place in screen-space, fragments failing the z-test are not shaded, essentially bringing the depth complexity down to one. There are also downsides such as its high memory bandwidth usage and making translucency and anti-aliasing difficult.
Until recently, WebGL had a roadblock for implementing deferred shading. In WebGL, a fragment shader could only write to a single texture/renderbuffer. With deferred shading, the g-buffer is usually composed of several textures, which meant that the scene needed to be rendered multiple times during the g-buffer pass.
"
But forward rendering requires a pass for each object or light, now thats a waste of shader power compared to the deffered rendering
http://www.cse.chalmers.se/edu/year/2011/course/TDA361/Advanced%20Computer%20Graphics/DeferredRenderingPresentation.pdf
"
Forward rendering
• Traditional method
• Single pass
– For each object
• Find all lights affecting object
• Render all lighting and material in a single shader
– Shader for each material vs. light setup combination
– Wasted shader cycles
• Invisible surfaces / overdraw
• Triangles outside light influence
Most of the text in this slide is extracted from a presentation by GUERRILLA GAMES
from DEVELOP CONFERENCE, JULY ’07, BRIGHTONForward rendering (cont.)
Forward rendering (cont.)
• Solution to material/light combination issue
• Multi-pass
– For each light
• For each object
– Add lighting from single light to frame buffer
– Shader for each material and light type
– Wasted shader cycles
• Invisible surfaces / overdraw
• Triangles outside light influence
• Lots of repeated work
– Full vertex shaders, texture filtering
Deferred Rendering
1. For each object
– Render surface properties into the G-Buffer
2. For each light and lit pixel
– Use G-Buffer to compute lighting
– Add result to frame buffer
• 3. Render Transparent Stuff (using forward
rendering)
Deferred Rendering Pro
• Complexity
• Shades only visible pixels
• Few shaders
• Post-processing stuff ready
• Lots and lots of Lights!
Deferred Rendering Con
• Lots of memory
• Bandwidth!
• Transparency
– G-buffers store one value per pixel
• Antialiasing
"
3.-As for the tiled textures, well, i just mentioned that sicne shinen is using 4k-8k textures and even with BC1 compression they are still to bif to fit on texture memory or in the edram its possible they devided the textures into tiles so that they could fit them in texture memory; i am not sure if they are using it or not but the first image of fast racing neo seems to tell us they are indeed using texture tiles for the terrain at least