Don't wanna say I called it... But I GOD DAMN called it. :P
Pascal based Tegra isn't going to be faster than the Xbox One.
TheLastStarFighter said:
Pemalite said:
I'm well aware of what you said. I just assume you were being sarcastic, otherwise what's the point in arguing in the first place?
|
You just keep repeating yourself, regardless of what people say has anything to do with the value of flops.
|
We have already established that you are either baiting or don't care.
dongo8 said:
I do understand that different allocations of the Floating Point Operations could theoretically slow down or speed up a build. BUT, isn't the processing of FLOPs dependant on the card, and not the FLOPs themselves? The programming of said FLOPs is the real slow down or expedition, I don't believe that it is the type. Like for instance, if a FLOP is programmed to be executed in 10 processor cycles, than it would be slower than a process that would need only 5. So the efficiency of programming plays a huge part in it, no? Also, what if the card has a parallel cycle running at the same time? It could theoretically do these processes in half the time that a single cycle processor could, right? This is all theoretical because from what I gather the load on the processing also plays a big part, if there are too many things running through that processor at the same time it creates a workload that is too heavy and it slows down the normally speedy processing.
So I understand for the most part how FLOPs work, but as for a speed benchmark for a computer since it depends heavily on how each FLOP is programmed I would say that using FLOPs is silly. Not only that, but it is nearly impossible to gauge since it depends on how efficiently each FLOP is programmed. HOWEVER, I stand by my original point, FLOPs are FLOPs because theoretically each processor is gauged by the same parameters. Yes, each FLOP is programmed differently, but when the processors FLOPs processing is determined they use the same theoretical vacuum. So it SHOULD be as it says. I definitely understand where you are coming from though.
|
You are partially right, but I think you need to cut your view point down so it's easier to reply to. :P
I think I'll use the Playstation 3 here as an example here... The Playstation 3's Cell processor had an insane theoretical single precision floating point ceiling, however it was only even partially achievable by using a variation of single precision floating point, that was iterative refinement.
When it came to other types of math, the chip faltered.
But the thing to keep in mind is that games are using all sorts of math all the time and the load is constantly changing, not just floating point.
It's why Jaguar, despite it having less flops, is able to out-pace Cell.
It's like a race, Jaguar is able to do 150Km/h for the entire race, the Cell is doing 100Km/h for the entire race, but when conditions are properly met (Iterative Refinement) It's able to do 200Km/h.
Do despite the Cell having a higher top-speed, it cannot maintain that under every circumstance... So it looses the race every single time.
This why Flops alone can't be used to compare chips.
Flops is like the "Mhz" myth of Old, people used Mhz to compare CPU's thinking it was some denominator for gauging performance, which for a time it was actually semi-accurate (Pun. - Not intended.)
JEMC said:
Thanks for posting!
With the same 256 "cores", I don't think it will be much powerful than the current X1 in games.
|
Agreed.
It all comes down to how much clockspeed nVidia can eek out of the chips, most of the architectural heavy-lifting/improvements had been done in Maxwell, so the difference will be pretty marginal at the same "core" count and clock.
Soundwave said:
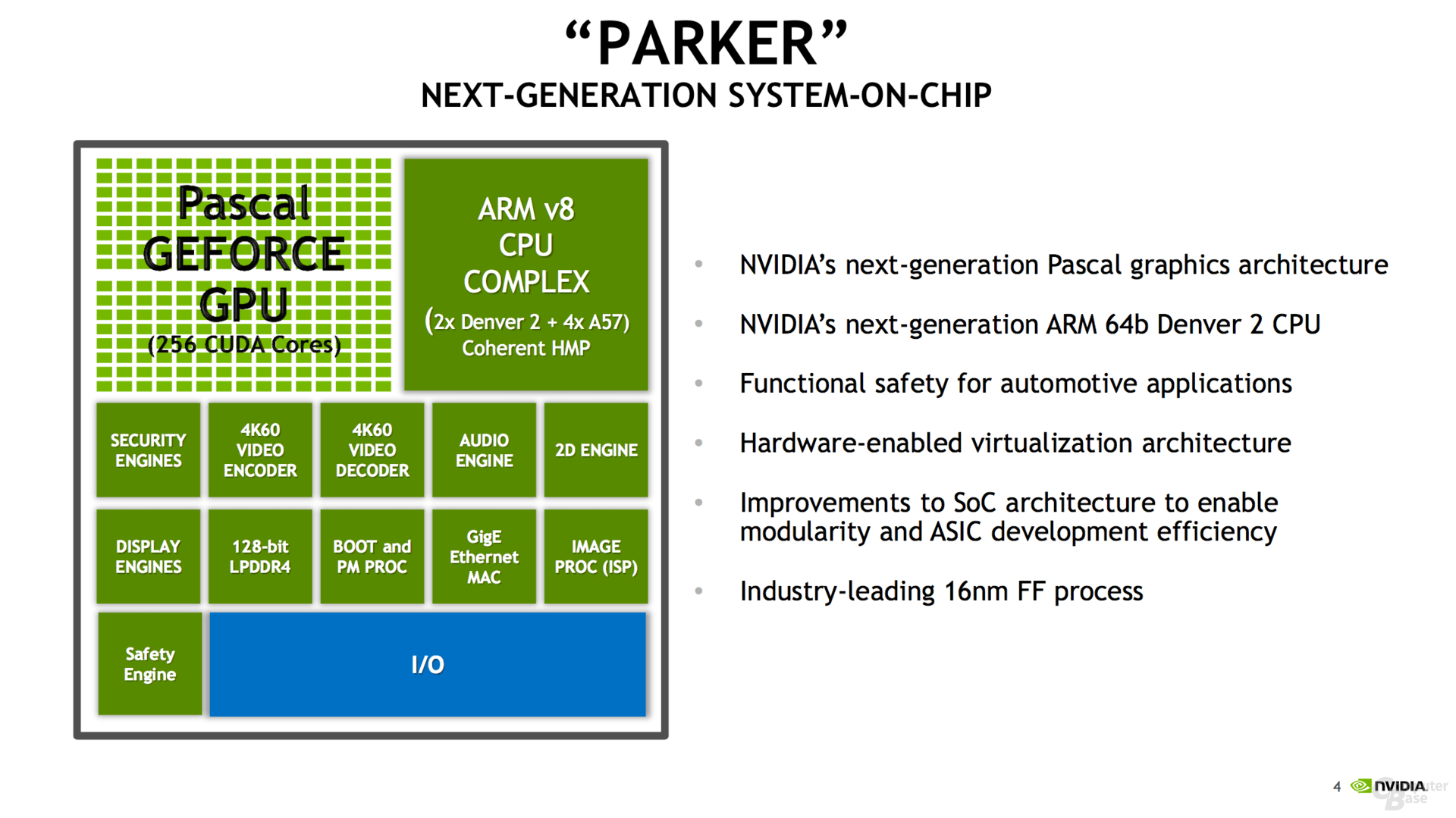
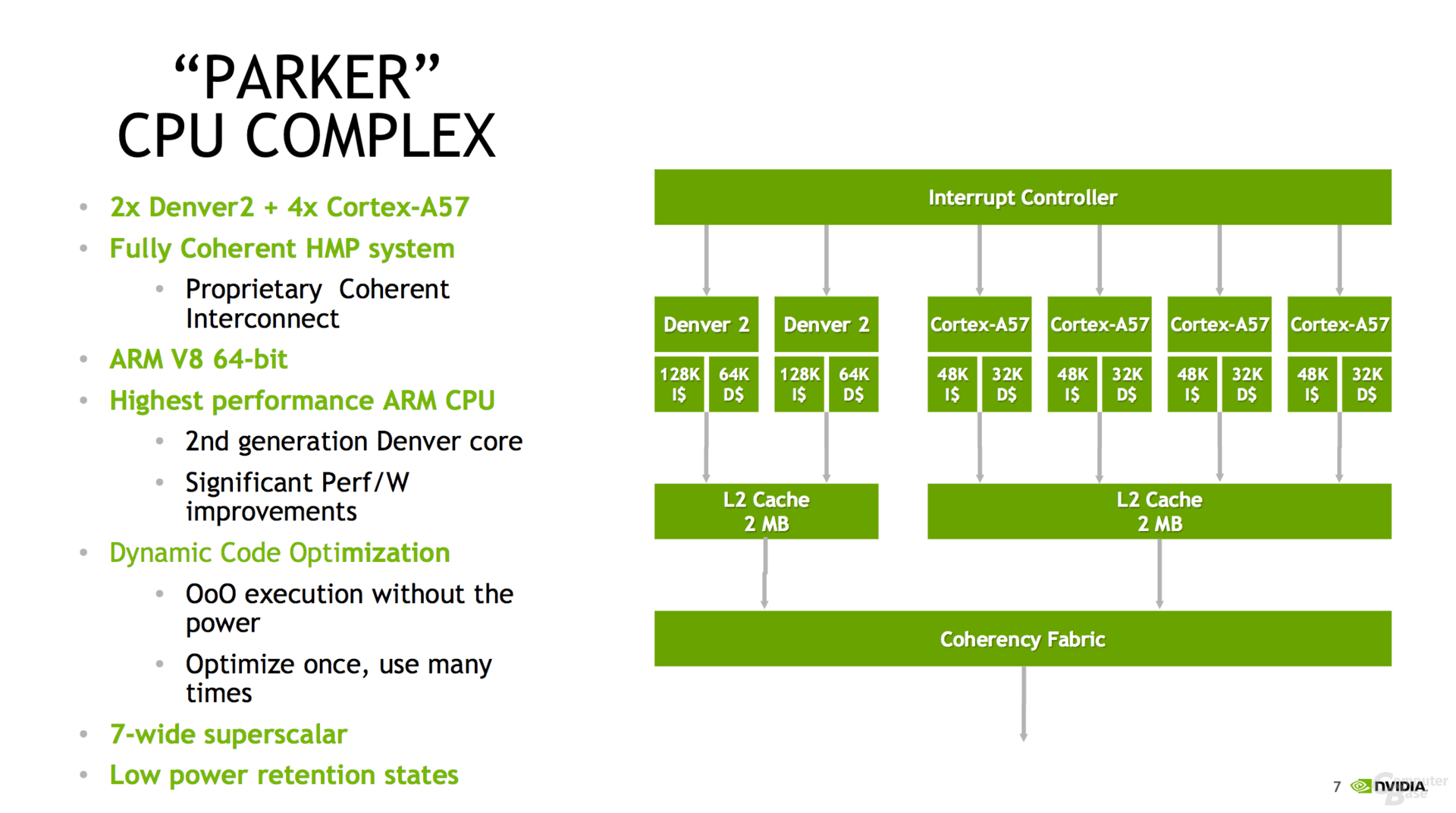
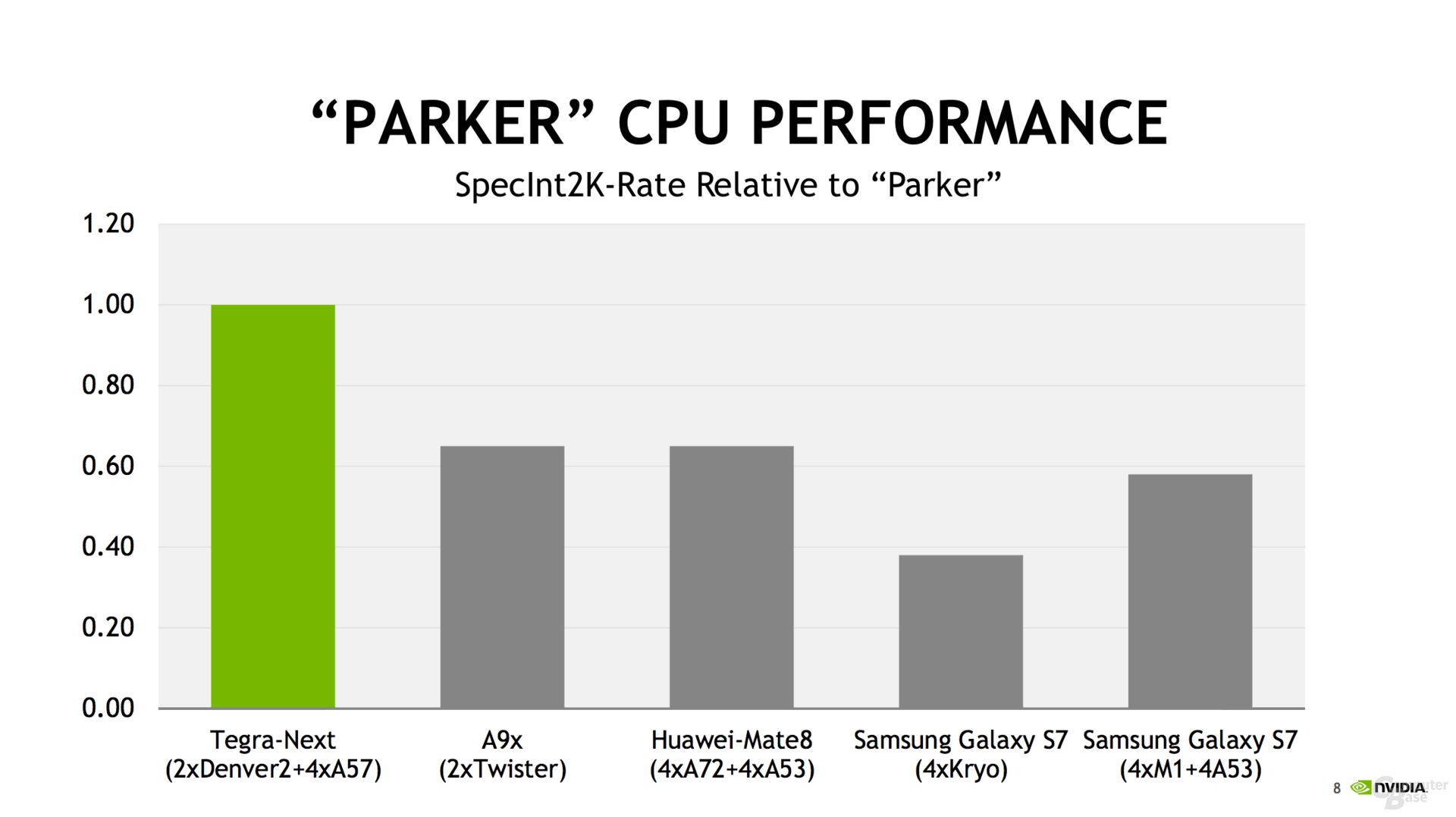
From NeoGaf is seems like the Parker Tegra (aka: Tegra X2) is 625 GFLOP (FP32) performance (vs 500 GFLOP for the Tegra X1) with a nice boost in CPU power and double the memory bandwidth to 50GB/sec.
This is great for a portable, though likely it would have to be underclocked.
However, it's not really that great for a console.
This also probably explains why DQXI on the NX has to be a custom version ... it likely cannot run the PS4 version.
|
Seems your "guess" came out to be true on the 128bit LPDDR4 memory bus, let's hope it translates over to the NX.
Soundwave said:
So basically based on nothing. Quite possible that DMP spurned by Nintendo for Nvidia also simply said "fine, we'll just make our own device", the way that's on their website implies it's some shitty low budget tablet.
Getting back to Tegra/Parker, Nvidia apparently said today the Parker/Tegra can get up to 1.5 TFLOPS, but they are obviously talking about FP16 mode there, so that would mean 750 GFLOPS in more standarad FP32.
750 GFLOPS .... welp. If they can deliver that in "docked/home power" mode I'll take it I guess. Shitty home performance given all things but at least it's a reasonable upgrade on the Wii U and not the GameCube to Wii all over again. I guess it could be the whole "Nvidia flops are 30% better than AMD flops" thing, lol, in which case, the reports of it being a little less than an XB1 would kinda line up exactly.
|
It would be Half Precision they were talking about.
We can expect a 50% improvement with the Pascal based Tegra over the Maxwell based Tegra when all the stars are in the correct order, probably mostly thanks to higher clock speeds, that's Pascals strong point as it leverages Finfet.
Soundwave said:
Nvidia says 750 GFLOP (1.5 GFLOP FP16) but the the slide says 625 GFLOP ... wonder what the discrepancy is (though it's not huge).
|
Could be Turbo.
Darc Requiem said:
125 GFLOPs is a significant difference when you are comparing 625 GFLOPS to 750 GFLOPS.
|
Not really.