







| Shadow1980 said: As for this "A.I. art" bullshit, it's just plagiarism on a mass scale. It's not an homage. It's not "inspired" by something else. It's tracing with extra steps. The computer just takes a bunch of assets without permission, smashes them all together, and regurgitates an amalgamation of all those stolen assets based on the parameters somebody types into a prompt. It's a soulless machine lacking all sentience, just following a program. It has no capacity to think abstractly, much less know what things like art or creativity even are in the first place. Whatever these "A.I.s" spit out shouldn't be subject to any legal protection. Even if we're generous enough to call "A.I. art" derivative works rather than just straight-up theft, those aren't subject to copyright either, regardless of whether the source material itself is still under copyright or is in the public domain. |
AI produced assets aren't copyrightable in the U.S (and I believe most other western countries.) So it really isn't much of an argument at this point. That's already been decided by the courts.
https://www.reuters.com/legal/ai-generated-art-cannot-receive-copyrights-us-court-says-2023-08-21/
Some countries, like Japan, are a lot more permissive though.
I will say what is happening technically isn't quite what you described. There really isn't some algorithm that manually stitches together different specific data of the training set nor is there a database that stores these images. It's not an automated collage-building tool "following a program." What is happening, simply, is that a mathematical function with billions of parameters (think of parameters like dials) is created through learning how to transform noise into different images by being trained on labeled image data that is made into noise. Then one is able to use this function with text inputs and get an image output, because it has learned how to reverse that noising into representations described by that text input. What is learned in this mathematical function, the "features" we call it, are aspects of images that make something "dog-like", "human-like", or "monet-style", etc., etc. As you make the image nosier different features of the image are extracted based on their specificity/generality because the noise can hide levels of detail and allow for different features to predominate. And it is from this that the model "learns" what the essential qualities of say a bird is, at multiple levels of detail, like the example below. 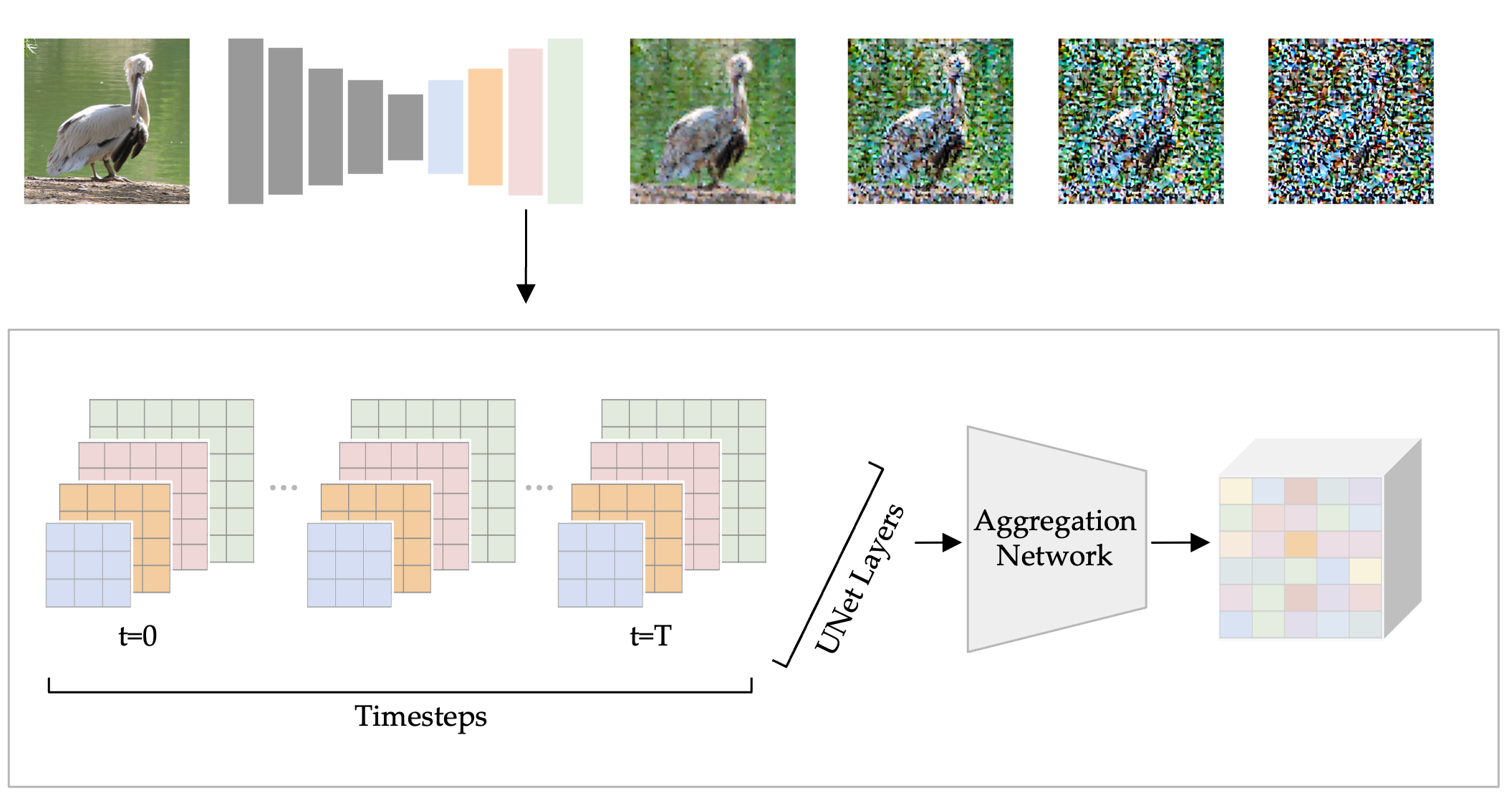
Having said that diffusion-models can learn the training sets quite well to the point that they can reproduce specific images (with some loss.) This is more likely if they are trained poorly with poor training sets, and is a behavior model engineers want to reduce.
It is unlikely that this is going to be the state of the art method in 5-10 years though. We'll likely have models that are actually doing something much more akin to what humans do by then. Right now the models are more like our (or probably better, a Mantis shrimp's) eyes, storing visual information into a part of the nervous system and being able to reproduce it from a sort of memory when triggered with the text or image input. In the future, there will be something more "intentional" behind the reproductions.
Edit: I would also like to point out that long before they were used for generative image modeling, these models were used for image-segmentation in medical applications. It just happens that when a model is good at being able to label parts of an image, it also is very good at reconstructing the image if you reverse the steps (and change the architecture a bit.) The distinction between classifiers and generators that is common in the lay-population isn't as strong in actual A.I research because classifiers can easily be made into generators with a trivial amount of effort. By making better classifiers we are making better generators.