










Overview of the very 8 core jaguar leaked in last years [Feb 2012] Durango specs:
The Durango CPU brings a host of modern micro-architectural performance features to console development. With Durango, a familiar instruction set architecture and high performance silicon mean developers can focus effort on content and features, not micro-optimization. The trend towards more parallel power continues in this hardware; so, an effective strategy for multi-core computing is more important than ever.
Architectural Overview
The Durango CPU is structured as two modules. A module contains four x64 cores, each running a single thread at 1.6 GHz. Each core contains a 32 KB instruction cache (I-cache) and a 32 KB data cache (D-cache), and the 4 cores in each module share a 2 MB level 2 (L2) cache. In total, the modules have 8 hardware threads and 4 MB of L2. The architecture is little-endian.
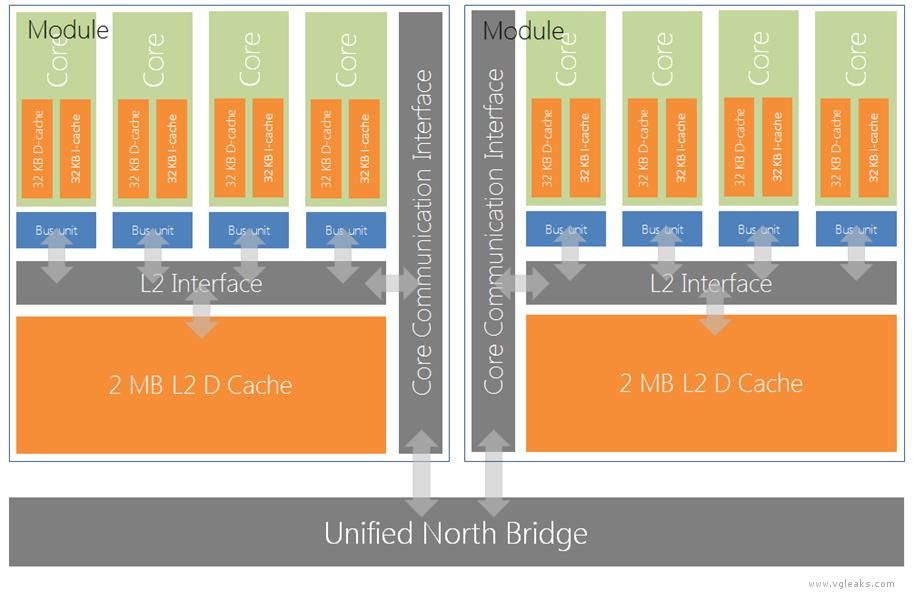
Four cores communicate with the module’s L2 via the L2 Interface (L2I), and with the other module and the rest of the system (including main RAM) via the Core Communication Interface (CCI) and the North Bridge.
Caches
The caches can be summarized as shown in the following table.
| Cache | Policy | Ways | Set Size | Line Size | Sharing |
| L1 I | Read only | 2 | 256 | 64 bytes | Dedicated to 1 core |
| L1 D | Write-allocate, write-back | 8 | 64 | 64 bytes | Dedicated to 1 core |
| L2 | Write-allocate, write-back, inclusive | 16 | 2048 | 64 bytes | Shared by module |
The 4 MB of L2 cache is split into two parts, one in each module. On an L2 miss from one module, the hardware checks if the required line is resident in the other module—either in its L2 only, or any of its cores’ L1 caches. Checking and retrieving data from the other module’s caches is quicker than fetching it from main memory, but this is still much slower than fetching it from the local L1 or L2. This makes choice of core and module very important for processes that share data.
| Memory access result | Cycles | Notes |
| L1 hit | 3 | Required line is in this core’s L1 |
| L2 hit | 17 | Required line is in this module’s L2 |
| Remote L2 hit, remote L1 miss | 100 | Required line is in the other module’s L2 |
| Remote L2 hit, remote L1 hit | 120 | Required line is in the other module’s L2 & in remote core’s L1 |
| Local L2 miss, remote L2 miss | 144-160 | Required line is not resident in any cache; load from memory |
Both L1 and L2 caches have hardware prefetchers that automatically predict the next line required, based on the stream of load/store addresses generated so far. The prefetchers can derive negative and positive strides from multiple address sequences, and can make a considerable difference to performance. While the x64 instruction set has explicit cache control instructions, in many situations the prefetcher removes the need to manually insert these.
The Durango CPU does not support line or way locking in either L1 or L2, and has no L3 cache.
This document does not cover memory paging or translation lookaside buffers (TLBs) on the cores.
Instruction Set Architecture
The cores execute the x64 instruction set (also known as x86-64 or AMD64); this instruction set will be familiar to developers working on AMD or Intel based architectures, including that of desktop computers running Windows. x64 is a 64-bit extension to 32-bit x86 , which is a complex instruction set computer (CISC) with register-memory, variable instruction length, and a long history of binary backward compatibility; that is, some instruction encodings have not changed since the 16-bit Intel 8086.
The x64 architecture requires SSE2 support, and Visual Studio makes exclusive use of SSE instructions for all floating-point operations. x64 deprecates older instruction sets: x87, Intel MMX®, and AMD 3DNow!®. x64 supports the following instruction set extensions:
- SIMD/vector instructions: SSE up to SSE4.2 (including SSSE3 for packing and SSE4a), and AVX
- F16C: half-precision float conversion
- BMI: bit shifting and manipulation
- AES+CLMULQDQ: cryptographic function support
- XSAVE: extended processor state save
- MOVBE: byte swapping/permutation
- VEX prefixing: Permits use of 256-bit operands in support of AVX instructions
- LOCK prefix: modifies selected integer instructions to be system-wide atomic
The cores do not support XOP, AVX2, or FMA3/4 (fused multiply-add).
Architecturally, the cores each have sixteen 64-bit general purpose registers, eight 80-bit floating point registers, and sixteen 256-bit vector/SIMD registers. The 80-bit floating point registers are part of x87 legacy support.
Performance
Durango CPU cores run at 1.6 GHz; this is half the clock rate of the Xbox 360’s cores. Because of this, it is tempting to assume that the Xbox 360’s cores might outperform Durango’s cores. However, this is emphatically not true, for the reasons described in the following sections.
Sub-ISA Parallelism and Micro-Operations
Like most recent high-performance x64 processors, the cores do not execute the x64 instruction set natively; instead, internally instructions are decoded into micro-operations, which the processor executes. This translation provides opportunities to parallelize beyond traditional superscalar execution.
Durango CPU cores have dual x64 instruction decoders, so they can decode two instructions per cycle. On average, an x86 instruction is converted to 1.7 micro-operations, and many common x64 instructions are converted to 1 micro-operation. In the right conditions, the processor can simultaneously issue six micro-operations: a load, a store, two ALU, and two vector floating point. The core has corresponding pipelines: two identical 64-bit ALU pipelines, two 128-bit vector float pipelines (one with float multiply, one with float add), one load pipeline, and one store pipeline. A core can retire 2 micro-operations a cycle.
Out of Order Execution
Xbox 360 CPU cores execute in-order (also called program order)the instructions in exactly the order the compiler laid them out. The Xbox 360 CPU has no opportunity to anticipate and avoid stalls caused by dependencies in the incoming instruction stream, and no compiler can eliminate all possible pipeline issues.
In contrast, the Durango CPU cores execute fully out of order (OOO), also called data order, since execution order is determined by data dependencies. This means the processor is able, while executing a sequence of instructions, to re-order the micro-operations (not the x64 instructions) via an internal 64-entry re-order buffer (ROB). This improves performance by:
- Starting loads and stores as early as possible to avoid stalls.
- Executing instructions in data-dependency order.
- Fetching instructions from branch destination as soon as the branch address is resolved.
Register Renaming
A low count of registers can cause execution of instructions to be unnecessarily serialized. Similar in concept to translating x64 instructions to micro-operations, register names used in the x64 instruction stream are not used as is, but are instead renamed to point at entries in a large internal physical register file (PRF)—Durango cores have a 64-entry, 64-bit, general-purpose PRF and a 72-entry, 128-bit, vector float PRF. With renaming, the processor can disentangle serialization by register name alone, and to get better throughput, it can push independent micro-operations to earlier positions in the execution order via OOO.
Speculative Execution
Instruction streams can be regarded as being divided into basic blocks of non-branching code by branches. CPUs with deep pipelines execute basic blocks efficiently, but they face performance challenges around conditional branches. The simplest approach—stall until the conditional is determined and the branch direction is known—results in poor performance.
The Durango CPU is able to fetch ahead and predict through multiple conditional branches and hold multiple basic blocks in its re-order buffer, effectively executing ahead through the code from predicted branch outcomes. This is made possible via the core tracking which registers in the PRF represent speculative results—that is, those from basic blocks that are not currently certain to be executed. Once a branch direction is determined, if the core predicted the branch direction correctly, results from that basic block are marked as valid. If the core mispredicted, speculative results (which may include many basic blocks) are discarded, and fetching and execution then begins from the correct address.
Store Forwarding
With in-order execution, a store to memory followed shortly by a load from the same location can cause a stall while the contents of memory (usually via an L1 line) are updated; the stall ensures that the load gets the correct result, rather than a stale value. On Xbox 360, this commonly encountered penalty is called Load-Hit-Store. On Durango, the cores have store-forwarding hardware to deal with this situation. This hardware monitors the load store queue, looking for memory accesses with the same size and address; when it finds a match, it can short-cut the store and subsequent load via the physical register file, and thereby avoid significant pipeline stalls.
Highly Utilized Out of Order Load Store Engine
A Durango core is able to drive its load store unit at around 80-90% capacity, even on typical code, because the combination of OOO, register renaming, and store forwarding massively reduces pipeline flushes and stalls, permitting highly effective use of L1 bandwidth. This improvement is partly the result of the load store unit being able to reorder independent memory accesses to avoid data hazards: loads can be arbitrarily re-ordered, and stores may bypass loads, but stores cannot bypass other stores.
By contrast, the load store hardware in the Xbox 360 is utilized at about 15% capacity on typical code, due to the many pipeline bubbles from in-order execution on the cost-reduced PowerPC cores. In conjunction with pipeline issues, the major factors in the Xbox 360’s throughput being as low as 0.2 instructions per cycle (IPC) are L1 miss, L2 miss, and waiting for data from memory.
Cache Performance
The Durango CPU uses 64-byte cache lines, which makes a process less likely to waste bandwidth loading unneeded data. On Xbox 360, ensuring effective use of cache lines for 128-byte lines can be tricky. While a Durango core’s L1 data cache is the same size as on Xbox 360, it is not shared between two hyper threads, and it has better set associativity. L2 is effectively three times the size, for each hardware thread, and it has better associativity: 512 KB per hardware thread on Durango versus approximately 170 KB per hardware thread on Xbox 360. L1 and L2 bandwidth will be more efficiently utilized on an automatic basis via prefetching, smaller cache lines, register renaming, OOO, and store forwarding.
Advanced Branch Predictor
Effective branch prediction increases the likelihood that speculative execution will execute the right code path. The Durango CPU cores have an advanced dynamic branch predictor, able to predict up to 2 branches per cycle. Rather than a branch direction, an actual branch address is predicted, meaning the instruction fetch unit can speculatively fetch instructions without waiting for resolution of the branch instruction dependencies and the resultant target. The first-level sparse predictor stores information about the branch target for the first two branches in a cache line, hashed by line address in 4 KB of storage. The sparse information also indicates if more than 2 branches are present in that line, and indexes into a second-level dense predictor, by using a 4-KB set-associative cache of prediction information for branches in 8-byte chunks. A branch target address calculator checks relative branch predictions as early as possible in the pipeline to permit discarding incorrectly fetched instructions. In addition, the prediction unit contains a 16-entry call/return stack and a 32-entry out-of-page address predictor.
Source: VGLeaks
